

introduction : une révolution visuelle pour l’ia
Le 16 avril 2025, OpenAI a secoué le monde de l’intelligence artificielle avec l’annonce de deux nouveaux modèles : o3 et o4-mini. Ces avancées ne sont pas de simples améliorations, mais marquent une véritable révolution, notamment grâce à l’intégration de la vision dans le raisonnement des ia. Pour la première fois, les modèles ne se limitent pas à traiter du texte, mais « voient » le monde, ouvrant des perspectives inédites. Cet article explore en détail les capacités, les performances et les implications de ces nouveaux venus.
o3 : la nouvelle référence en matière de performance
o3 se positionne comme le modèle le plus avancé proposé par OpenAI à ce jour. Ses performances sont impressionnantes, surpassant ses prédécesseurs sur des tâches complexes comme les mathématiques, le codage et les sciences expérimentales. Les résultats obtenus sur des benchmarks de référence, tels que codeforces ou swe-bench, sont significativement meilleurs. Selon les tests internes, o3 réduit de 20% les erreurs majeures par rapport au modèle o1.
autonomie et intégration des outils : un bond en avant
Au-delà de ses performances, o3 se distingue par une meilleure autonomie. Il est capable de mobiliser les outils mis à sa disposition dans chatgpt, comme la navigation web, l’exécution de code, la génération d’images et la lecture de fichiers, sans avoir besoin d’instructions explicites. Cette capacité d’adaptation renforce sa pertinence dans les échanges longs et les requêtes complexes. De plus, o3 dévoile les étapes de sa réflexion avant de fournir une réponse, offrant ainsi une transparence nouvelle.
o4-mini : un compromis intelligent
En parallèle de o3, OpenAI a lancé o4-mini, une version plus légère et moins coûteuse. Bien qu’elle soit plus compacte, o4-mini n’en demeure pas moins performante, surpassant o3-mini sur plusieurs tests. Ce modèle est conçu pour être accessible, avec des limites d’usage plus élevées, ce qui le rend idéal pour les utilisateurs intensifs.
des performances impressionnantes pour o4-mini
o4-mini excelle dans les domaines des mathématiques, du codage et des tâches visuelles, offrant des performances remarquables pour sa taille et son coût. Il bénéficie, comme o3, de l’intégration complète aux outils chatgpt et possède les mêmes capacités de raisonnement multimodal. Il peut traiter des documents complexes, résoudre des problèmes mathématiques et extraire des données d’images avec une grande rapidité.
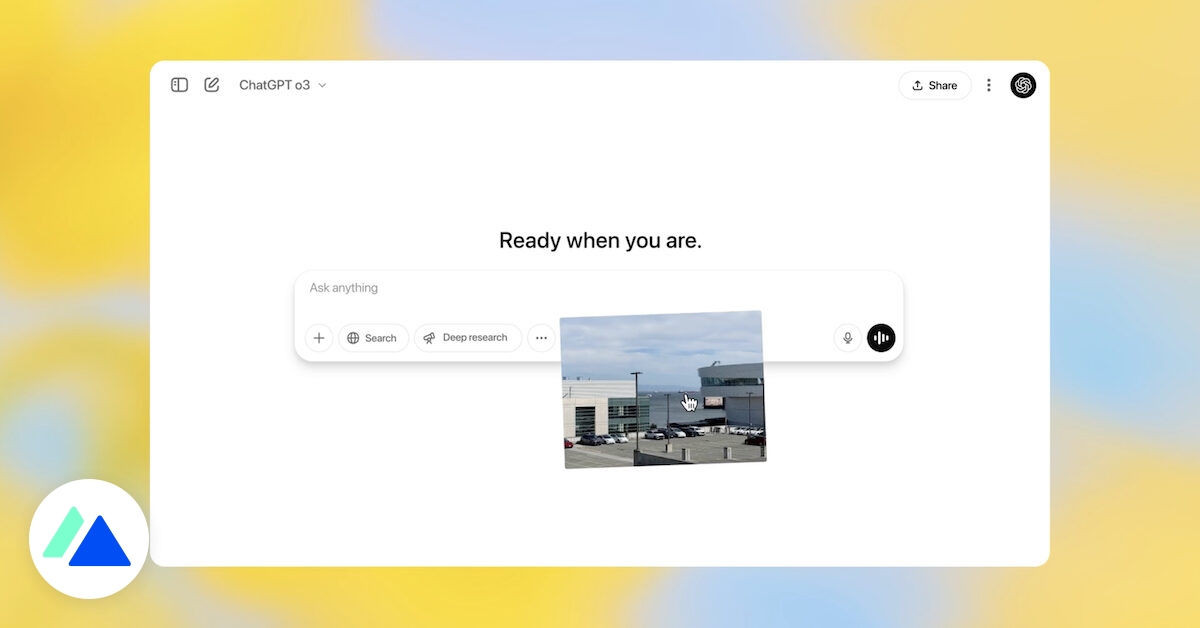
la vision : un nouveau terrain de jeu pour chatgpt
La nouveauté la plus marquante de ces modèles est leur capacité à raisonner avec des images. Contrairement aux générations précédentes, o3 et o4-mini peuvent analyser des documents visuels, les modifier (zoom, rotation, recadrage) pour en extraire des informations pertinentes. Cette fonction est intégrée nativement aux modèles, sans nécessiter d’outils externes.
une révolution dans la compréhension visuelle
Grâce à cette avancée, les modèles peuvent traiter des images imparfaites ou incomplètes, comme des feuilles manuscrites mal cadrées ou des photos de tableaux prises de travers. Ils sont capables d’analyser des documents scientifiques, de lire des graphiques et de répondre à des questions basées sur des cartes ou des panneaux de signalisation. OpenAI évoque un changement de paradigme où l’image devient une source d’information à part entière.










Premier commentaire ?